句構造木は,支配的な変形文法のみならず,LFG,HPSG,RRGの論文などでも広く使われるせいか,スタイルファイルは比較的たくさんあります.大きく分けて,LaTeX自体の描写機能を利用するもの,PSTricksなどのpostscriptの描写機能を利用するものがあります.前者の方は手軽で,postscriptを介さなくて良い(dvipdfm(x)などでpdfを生成できる)というメリットがありますが,あまり複雑なことはできません.後者の方はパワフルで,多様な句構造木を描くことができますが,dvipsを介してpsファイルを生成する必要があります.よく知られているものは以下のようなものがあります.
【2013.09.13.追記】TikZというpostscriptを介さなくても強力な描写能力のあるパッケージを利用したものが近年主流になりつつあるので,そちらの情報をココに追加しました.
LaTeXのみで可能なもの
- parsetree.sty(解説も含めコチラから入手可能)
- qtree.sty(解説も含めコチラから入手可能)
- treeprint.sty (epic.sty, eepic.styと一部の機能にはeclarith.styを読み込む必要がある.日本語の解説も含め,すべてコチラから入手可能)
- xyling.sty(解説も含めコチラから入手可能)
Postscript/PStricksが必要なもの
- rtrees.sty(用法はスタイルファイルの中に記載)
- pst-jtree.sty(解説も含めコチラから入手可能)
- rrgtrees.sty(RRGに特化されたスタイル.他の理論への応用は困難.解説も含めコチラから入手可能)
- tree-dvips.sty(tree-dvips.proが必要.このスタイル自体にノードを配置する機能はなく,tabular環境などで配置済みのノードを線で結ぶのみ.解説も含め,すべてコチラから入手可能)
TikZを利用するもの
サンプルのソースと結果
以下で,parsetree.sty, qtree.sty, treeprint.sty, rtrees.sty, forest.styについて,簡単な解説,ソースの記述法,結果を比較してみます.各スタイルの細かい用法や微調整,カスタマイズについては割愛します.あくまでノーマルな状態で使うとどうなるかという結果です.なお,数学環境でスモールキャピタルを使っていますので,サンプルのソースをコピーして試す場合は,以下のようにプリアンブルに書いておいて下さい.
\DeclareMathAlphabet{\mathsc}{OT1}{cmr}{m}{sc}
parsetree
- ソースの記述自体は非常に簡単.
- 他のスタイルファイルと組み合わせると,比較的複雑な木を書くことができる.
- 3分岐までの枝しか書くことができない.
- 丸括弧とチルダに意味があるため,これらの記号をテキストとして使用する場合,特別な処置が必要で結果面倒なこととなる.
- 原因は不明だがBeamerで使うことができない.
以下にサンプルのソースとその結果をあげておきます.
\begin{parsetree}
(.IP.
(.DP. ~ .that girl.)
(.I$'$.
(.I. `did')
(.VP.
(.V. .hate.)
(.DP. ~ .this man.)
)
)
)
\end{parsetree}
\begin{parsetree}
(.S.
(.\begin{tabular}{c}NP\\
$\uparrow \mathsc{subj} = \downarrow$
\end{tabular}. ~ .学生が.)
(.\begin{tabular}{c}VP\\
$\uparrow = \downarrow$
\end{tabular}.
(.\begin{tabular}{c}PP\\
$\downarrow \in \uparrow \mathsc{adj}$
\end{tabular}. ~ .居酒屋で.)
(.\begin{tabular}{c}NP\\
$\uparrow \textsc{obj} = \downarrow$
\end{tabular}. ~ .酒を.)
(.\begin{tabular}{c}V\\
$\uparrow = \downarrow$
\end{tabular}. .飲んでいた.)
)
)
\end{parsetree}
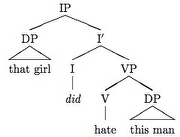

qtree
- parsetree同様ソースの記述はシンプル.
- 数行にわたるノードも,普通に改行するだけで書くことができる.
- ノードが大きくなったり,分岐数が増えていくと,バランスがおかしくなって予想以上に巨大な木になる傾向がある.
以下がサンプルのソースとその結果です.
\Tree [.IP \qroof{that girl}.DP
[.I$'$
[.I {\em did} ]
[.VP [.V hate ]
\qroof{this man}.DP
].VP
]
]
\Tree [.S \qroof{学生が}.{%
NP\\$(\uparrow \mathsc{subj}) = \downarrow$}
[.{VP\\$\uparrow = \downarrow$}
\qroof{居酒屋で}.{%
PP\\$\downarrow \in (\uparrow \mathsc{adj})$}
\qroof{酒を}.{%
NP\\$(\uparrow \mathsc{obj}) = \downarrow$}
[.{V\\$\uparrow = \downarrow$} 飲んでいた ]
]
]


treeprint
- 枝の長さなどの微調整も可能で,仕上がりのバランスが良い.
- postscriptに依存していないにも関わらず,かなりの描写能力がある.
- ソースの記述量が比較的多め.
- ノードのサイズが大きくなると,全体のバランスが崩れやすい.
以下がサンプルのソースと結果です.
\tree{IP}
\subtree{DP}\omittree{that girl}\endsubtree
\subtree{I$'$}
\subtree{I}\leaf{\em did}\endsubtree
\subtree{VP}
\subtree{V}\leaf{hate}\endsubtree
\subtree{DP}\omittree{this man}\endsubtree
\endsubtree
\endsubtree
\endtree
\tree{S}
\subtree{\begin{tabular}{c}
NP\\$(\uparrow \mathsc{subj}) = \downarrow$
\end{tabular}}
\omittree{学生が}
\endsubtree
\subtree{\begin{tabular}{c}
VP\\$\uparrow = \downarrow$
\end{tabular}}
\subtree{\begin{tabular}{c}
PP\\$\downarrow \in (\uparrow \mathsc{adj})$
\end{tabular}}
\omittree{居酒屋で}
\endsubtree
\subtree{\begin{tabular}{c}
NP\\$(\uparrow \mathsc{obj}) = \downarrow$
\end{tabular}}
\omittree{酒を}
\endsubtree
\subtree{\begin{tabular}{c}
V\\$\uparrow = \downarrow$
\end{tabular}}
\leaf{飲んでいた}
\endsubtree
\endsubtree
\endtree


rtrees
- ソースの記述は単純.
- AVMを埋め込んだ木を描く機能が含まれている.
- 簡単な句構造でも,割と大きくなってしまう傾向がある.
- 普通の木でノードが大きくなると,枝がフラットになる傾向がある.
以下がサンプルのソースと結果です.AVMの木も書くことができるため,そちらも追加してあります.
\begin{tree}
\br{IP}{\br{DP}{\tlf{that girl}}
\br{I$'$}{\br{I}{\lf{\em did}}
\br{VP}{\br{V}{\lf{hate}}
\br{DP}{\tlf{this man}}
}
}
}
\end{tree}
\begin{tree}
\br{S}{\br{\begin{tabular}{c}
NP\\$(\uparrow \mathsc{subj}) = \downarrow$
\end{tabular}}{\tlf{学生が}}
\br{\begin{tabular}{c}
VP\\$\uparrow = \downarrow$
\end{tabular}}{%
\br{\begin{tabular}{c}
PP\\$\downarrow \in (\uparrow \mathsc{adj})$
\end{tabular}}{\tlf{居酒屋で}}
\br{\begin{tabular}{c}
NP\\$(\uparrow \mathsc{obj}) = \downarrow$
\end{tabular}}{\tlf{酒を}}
\br{\begin{tabular}{c}
V\\$\uparrow = \downarrow$
\end{tabular}}{\lf{飲んでいた}}
}%VP
}%S
\end{tree}


\begin{avmtree}\avmfont{\sc}
\br{\[cat & S\\
head & \@{3}\|pos {\it verb}\\
spr & \q<~~~\q>\\
comps & \q<~~~\q>\]}{%
\br{\@{1}NP}{\tlf{that girl}}
\br{\[cat & VP\\
head & \@{3}\|pos {\it verb}\\
spr & \q<\@{1}\q>\\
comps & \q<~~~\q>\]}{%
\br{\[cat & V\\
head & \@{3}\|pos {\it verb}\\
spr & \q<\@{1}\q>\\
comps & \q<\@{2}\q>\]}{{\lf{hated}}}
\br{\@{2}NP}{\tlf{this man}}
}%VP
}%S
\end{avmtree}

forest
- ソースの記述は単純.
- TikZの機能が利用できるので,描写能力がひじょうに高い.
- pdfLaTeXやXeLaTeXなどでも使える.
- pstricksと併用できないので,例えばLFGでよくある句構造木とAVMを結ぶといった描写が難しい.
以下でサンプルのソースと結果を示しますが.その前に,標準的な見た目の句構造木にするためにここでは以下のようにパラメータを設定しておきます.これをプリアンブルにでも書いておいて下さい.個々のパラメータの意味はスタイルの解説書を参照の上,変更したい場合は適宜調整して下さい.この設定を適当な名前(ここでは`sn edges’)で保存して,それを句構造木を描く時に呼び出すことになります.
\forestset{sn edges/.style={
for tree={
parent anchor=south, child anchor=north,
calign=fixed edge angles,
calign primary angle=-65, calign secondary angle=65,
align=center, base=t},
delay={
where content={}{shape=coordinate,
for parent={for children={anchor=north}}}{}}
}}
ではサンプルとその結果です.
\begin{forest}
sn edges [ IP [ DP [ that girl, triangle]]
[ I$'$ [ I [ {\em did}]]
[ VP [ V [ hate]]
[ DP [ this man, triangle]]]]]
\end{forest}
\begin{forest}
sn edges [ S [ NP\\{($\uparrow \mathsc{subj}) = \downarrow$}
[ 学生が,triangle]]
[ VP\\{$\uparrow = \downarrow$}
[ PP\\{$\downarrow \in (\uparrow \mathsc{adj})$}
[ 居酒屋で,triangle]]
[ NP\\{($\uparrow \mathsc{obj}) = \downarrow$}
[ 酒を,triangle]]
[ V\\{$\uparrow = \downarrow$}
[ 飲んでいた]]
]
]
\end{forest}


forest.styはひじょうに色々なことができるので,ぜひ解説書を見て欲しいのですが,drawで移動の軌跡を描いたものを追加のサンプルとして載せておきます.ここではnameでノードの名前をつけて,\drawでそれを結んでいます.その際ノードから線の出力方向(out)と着地方向(in)を指定したり,線の種類(矢印なのか点線なのかなど)を変えたりできます.さらにTikZの機能を呼び出して,箱を描いたりできます.
\begin{forest}
sn edges [ CP [ DP,name=specCP]
[ [~]
[ $v$P,tikz={\node [draw,red,fit to tree]{};}
[ DP,name=specvP]
[ $v'$ [$v$]
[ VP [ $t$,name=specVP]
[ V$'$ [ V]
[ $t$,name=VPcomp]]]]]]]
\draw[->] (specVP) to[out=south west,in=south] (specvP);
\draw[->,dotted] (VPcomp) to[out=south west,in=south] (specCP);
\end{forest}

まとめ
それぞれのスタイルに長所と短所があるので,自分がどのような木を書く必要があるのかを考えて,適宜選択すると良いと思います.シンプルなbinaryの木しか描かず,プレゼンにBeamerを使わないなら,parsetree.styが簡単で良いでしょう.Beamerでも使いたければqtree.styが良いかもしれません.もう少し微調整もしたいし,複雑な木を書く可能性もあるが,postscriptに依存しないものがよいのなら,treeprint.styがお勧めです.一方,HPSGなら,やはりAVMが簡単に埋め込めるrtrees.styが使いやすいでしょう.
【2013.09.13.追記】TikZが広く普及しつつあり,forest.styのようにpostscriptに依存せず強力な描写能力を持ったスタイルが今後主流になっていくかもしれません.
なお,サンプルのソースでは,独自のマクロなどはあえて使っていないので,tabular環境や数学環境を含んだ複雑なものになっていますが,特定のよく使う表現はマクロにしてしまえば,実際はもっと簡単に記述することができます.